This article is cross-posted on medium.com
In July 2019 I gave the opening keynote at the useR! Conference, the R language’s premiere gathering that has occurred annually throughout the world since 2004. It was, needless to say, an incredibly huge honor. And perhaps an unexpected one for a marine ecologist. But the R community has been so impactful on my science and life, and this was the opportunity to try to articulate its importance back to the community and to welcome others. I am really proud of my talk, and am thankful for everyone who helped me build up to it over the years. This post is not a summary of the talk, but a few highlights, thoughts that are in development, a few responses to un-asked questions during the Q&A, and links to resources and conversations.
Quick links:
- keynote video (starts at 46:30)
- keynote slides (press
pto see presenter notes, since on-slide text is sparse) - artwork by Allison Horst (available for download and reuse)
- useR website
- #user2019 on Twitter
- blog by Mozilla
R for better science in less time

My keynote talk was called “R for better science in less time” and is about how open software and teamwork can supercharge environmental science. And specifically, how R as a language and as a community have been so impactful on my science and on my life, so that now I am focused on passing forward what I’ve learned. While the message is relevant to many different fields, I focus on environmental science because that is where my expertise lies as a marine-scientist-turned-marine-data-scientist, and that is where there is a pressing need as scientists tackle how humans can live sustainably in a changing climate.
In my keynote I shared a lot about Openscapes and what motivates the Champions mentorship program. That motivation comes from my own experience struggling with data (both alone and with collaborators) and getting through it with mentorship and teamwork, centered around open data science. My three big take-homes were that open data science is a mindset, that teamwork starts with openness, and that to be most effective we should harness the power of welcome. I won’t build out those lessons learned here, but I will highlight some of what motivates my work — see options above to read and watch the whole story (or check out @fmic_’s live-tweets!).
But first I wanted to say thank you again to everyone that helped me prepare for the talk. In particular, thank you Allison Horst, who coached me weekly and designed beautiful, original artwork to help convey my ideas. And thank you also to Yihui Xie, JJ Allaire et al for the RMarkdown suite: I made the slides in R using xaringan, and published them on GitHub gh-pages. #opendatascience and #teamwork #forthewin.
Environmental open data science
This is the vision I see for environmental science: Where the elements that environmental scientists are great at — like theory, and experimental design, and data collection — are streamlined using open data science to help us uncover and communicate environmental solutions faster. The center of this illustration (the import > tidy > transform/visualize/model > communicate cycle that accompanies Wickham & Grolemund’s definition of data science) here is ringed by communities and support that supercharge innovation and teamwork. These are the communities that my Ocean Health Index team has found so critical to our success.
This complete picture is so important for the amazing scientists studying climate changes’ affects on the environment (including food security and disease transmission). But currently this is not the norm.

Currently, environmental science looks like this. We are rarely taught how to work responsibly with data or have formal training with coding or computing, which leaves us largely on our own to learn how to analyze our data. This means scientists learn on their own in pockets of opportunity but are largely unsupported at broader institutional levels, and we spend a lot of time struggling and reinventing the wheels of data analysis when we are trying to be focused on science questions (see this excellent publication by Hampton et al 2017). And often scientists are not supported even at level of the research group, which is already a science team and should be so in terms of data.
Helping complete this picture drives my work now. Openscapes is all about how to best complete this picture by introducing open data science and teamwork to supercharge scientific research.
Open data science — teamwork feedback loop
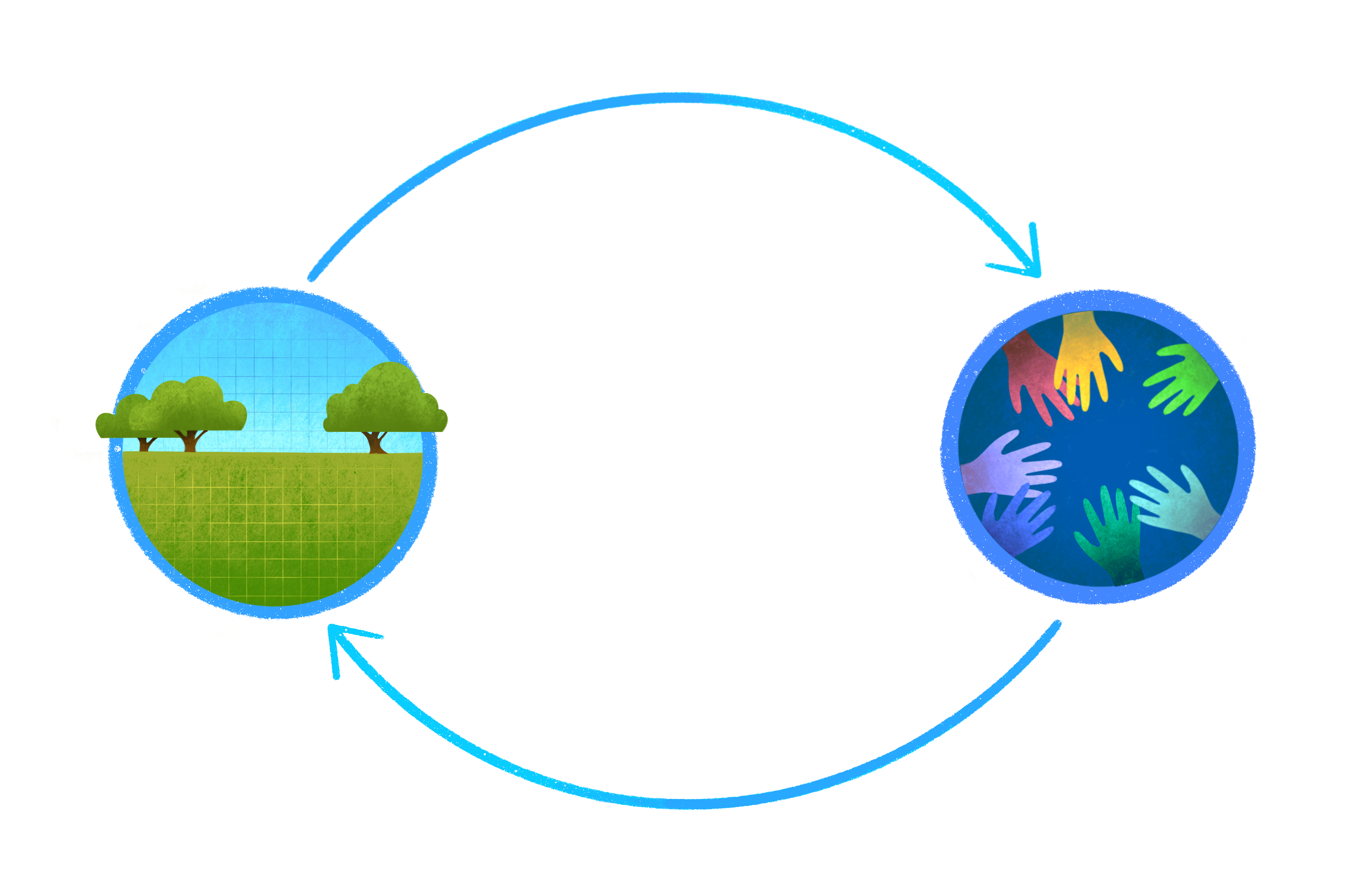
Open data science and teamwork are so powerful together, and I’ve been thinking about them together as a beautiful feedback loop. Starting on the left: learning and using similar open software promotes and streamlines teamwork. And from the right: working as a team better equips you to learn open practices data science.
For example, using shared conventions like the tidyverse in R can reduce friction when it comes to running each others’ code, which can then open up time for more thoughtful suggestions and collaboration. The relationships and trust built within the team from these experiences can prime them to improve upon their workflows — they might be more willing to introduce GitHub to their team as a way to reduce the friction that comes from from file-sharing. This will then make it easier to onboard new members to the team, and continue strengthen relationships and skillsets.
This is a loop that feeds back on itself, which each fueling the other. Maybe it’s more like a spiral, because it gets tighter and tighter? I think that this is really what is going on in the central portion of the environmental open data science illustration above: those communities ringing the data science workflow. It’s this feedback and this fueling that is so powerful, and it is not limited to the traditional definitions of teams — it creates whole communities that innovate together. And it’s also the part that is currently missing from the way we do environmental science.
So my work with Openscapes is harness the power of welcome to … welcome more environmental scientists into this feedback loop. This means being kind and empathetic when discussing open data science with research groups, and help them operate more like a team in an open data science context. With Openscapes, we started on the teamwork side but immediately framed it around open data science and then continued to loop around. Build more trust, discuss more tools. Discuss current norms in the research group, discuss available open tools and practices. Create a code of conduct, Create a GitHub organization. The first Openscapes cohort has had awesome acheivements and momentum, and I’m excited to revisit and improve upon the program to help science teams get into this feedback loop as effectively as possible!
R is the force that enables us to do better science in less time
I like to talk about all of this in terms of metaphors with Star Wars, hence the title slide :).

This is Luke Skywalker after he crashed his plane in the swamp on Dagobah.
He cannot solve the the challenge in front of him with the skillsets he has, and it is super demoralizing. And if you imagine him attempting to use whatever pulleys and ropes he might have with him, you know it wouldn’t be pretty, it wouldn’t be reproducible, and it probably wouldn’t get him where he needs to be on time. But luckily what happens next is that he meets Yoda —

And Yoda has a skillset to solve Luke’s problem in a way Luke never imagined was possible. He uses the Force.
And this is going to change Luke’s life, both in terms of skills and mindset. Luke can see what’s possible and he can learn these skills from Yoda. And he will be able to not only solve his current challenge, but it will broaden his whole mind to what is possible in the future and the scale of the challenges he will take on.
But Luke didn’t go on to defeat the Empire himself, he had a whole community.

And this community is powerful because of the diversity of backgrounds and expertise, and although not everyone is a Jedi, everyone contributes in really critical ways. So to recap:

R is the Force that enables us as scientists to do better science in less time.
It empowers us to get our own data out of the swamp. And it empowers us and build off of our confidence and experiences and broaden the scope of scientific challenges that we can tackle, which for environmental scientists, includes food security, disease transmission, and climate change.
–
Over the years folks have asked who is Yoda in this analogy. The answer is, it’s relative. To me, Yoda is many of the people at useR! and in the #rstats community; they are the developers of the R tools and packages I use. In this scenario, they are the Jedis and feel more like Rey. But when I mentor with Openscapes and lead trainings with RLadiesSB, Eco-Data-Science, NCEAS, and The Carpentries, folks see me as Yoda, and they feel like Rey. And I think that’s an important part of this; even if you don’t feel like THE Jedi or expert, you probably are to some people, and you can step up into that role and help welcome them to the power of the Force. And that can start immediately: you can champion R as the Force now.
This is a good place to end the highlights from my talk and answer a few questions that were submitted in Toulouse after my keynote.
Q&A
Do we need to talk about “open data science” instead of just “open science”
One of the questions I was asked after the talk was about whether “open data science” is needed as a distinction from “open science”; isn’t it already a part of open science as a whole? I don’t think I answered that question completely in the moment (I was pretty fried) so I thought I’d try to articulate my response a bit here.
To me, “open data science” is more about bringing “open” to the topic of “data science” rather than distinguishing “data” in “open science”. I think the concepts of openness are really critical when we think about data science and coding. My coding experience began with proprietary software and sluggish sharing (for both technical and mindset reasons), so I think it’s important to be explicit and talk about openness and code together. Openness in data science can help daylight “black box” algorithms. And it can also facilitate innovation through reusing and remixing code that we can run on our own machines because the language is open source and we share it openly.
With every PhD student generation, do you feel that it becomes easier to convince them to engage in Open Science? Or is there recurring resistance?
Yes, I think it is getting easier. I think that the new (now?) generation of scientists are much more willing to engage in open science. They have grown up sharing (Instagram, Facebook, Google Docs), and they help bring the idea of sharing openly to the scientific community. And I’m excited to see this because there is great opportunity for open practices to not only accelerate and amplify collaboration and scientific discoveries, but, importantly, to be valued and rewarded within the academic system. We really need to favor openness and team science, because no one can do it all, and we need to break down the expectation that they should be able to.
How did u convince ur boss to have believe in something he didn’t have knowledge about?
Convincing our boss that open data science was worth our time to learn required a combination of trust, demonstrating its value in ways that he cared about, and absolute necessity.
In terms of trust, he already gave us independence in our tasks, valued our judgment, and welcomed feedback. This had been established within the team for months to years, so it was a collaborative environment before we even began talking about open data science.
We were able to demonstrate value in ways that he cared about: we showed him that R and GitHub would save time. And we were clear that it would not be immediate; it might take us three days to do something in R that we could produce in Excel in a half a day — but it will take just a half-hour next week. And the week after that. We demonstrated how nimble we were to rerun analyses with small changes to parameters or subsets of data, and that these skills would be valuable not only for the current project but for projects to come. And visualizations helped a lot too, as well as interactive graphics and gifs (super great for demonstrating change over time, which ecologists think about a lot).
This argument was helped because of absolute necessity. We had deadlines approaching and we were spending time retracing our steps instead of taking the next steps forward. We needed a better way to work: it was not sustainable to have to waste so much time doing forensics in our emails and file systems to try to figure out what we had done and why in order to advance our analyses. For a dramatic analogy, it was like accepting that candles were not producing enough light anymore and that we needed to wire our house for electricity. It meant overcoming inertia and the time it takes for changing this infrastructure, but it means that we can be more efficient in the long run.
How can you keep the balance between sharing and open data and protecting the data while working in a private company?
The advice that comes to mind is to “be as open as possible, and as closed as necessary”. Folks have developed ways to summarize or anonymize sensitive data before sharing, and it is also possible to share code or methods, etc without sharing the data. I strongly believe that there are many ways to work openly even if you can’t share your data; you can share slides from talks, teaching materials from your courses, snippets of code or methods; you can also blog, you can publish in open access journals, you can engage on social media and in local communities. It’s an exciting time for open science.
I also think that part of sharing and openness is being aware and engaged with what is possible on the software side so that your current, individual skillsets or experiences don’t limit your imagination.
To go back to the Star Wars analogy, when Luke was weighing his options of how to get his plane out of the Dagobah swamp, he never would have considered the Force unless he saw what Yoda was able to do. And that develops a mindset where even if you have not seen exactly everything that is possible, you start to expect that it is possible. Luke lifted up that rock? And R2? Well, then, he should be able to do an X-Wing. Twitter is a great tool to keep tabs on new ideas and projects so that you broaden your expectations of what’s possible (see the next question).
On the science side, I think sometimes our uneasiness about sharing is because we do not know what’s possible, and it seems like a lot of extra work. If your experience with sharing (smallish) data has been limited to written text in email with attachments, the idea of sharing broadly and keeping things up to date seems like a huge task. But if your whole workflow uses tools that streamline your day-to-day organization and analyses, then sharing requires much lower activation energy. And I think the mindset shift precedes expertise. When you not only see but have a touch of experience with how a GitHub account and a bit of Markdown gives you a whole new, update-able communication platform, it really does help spark a change in mindset. And while there is time involved in sharing information, the time-saving benefits and power in the near and long term are worth the investment (just like they are for Luke and Rey).
How to use Twitter effectively to improve our skills and share our experience?
My advice for Twitter is to start off small and deliberately. Use it to listen and learn, and then you can gradually build up the courage to like and retweet things. And remember that liking and retweeting is not only a way to engage with the community yourself, but it is also a way to welcome and amplify other people.
If you’re joining twitter to learn R, I suggest following @hadleywickham, @JennyBryan, @rOpenSci, @WeAreRLadies. Listen to what they say and who joins those conversations, and follow other people and organizations. You could also look at who they are following. Also, check out the #rstats hashtag. This is not something that you can follow (although you can have it as a column in software like TweetDeck), but you can search it and you’ll see that the people you follow use it to help tag conversations. You’ll find other useful tags as well, within your domain, as well as other R-related interests, e.g. #rspatial. When I read marine science papers, I see if the authors are on Twitter; I sometimes follow them, ask them questions, or just tell them I liked their work!
In Openscapes I talk through the following examples to show how I use Twitter to learn new things and keep tabs on (some of!) what’s going on in R. I miss a lot because I’m not on Twitter all the time. And that is OK. There is too much goodness to know it all, and I am by no stretch of the imagination on top of it all or experienced with everything folks are developing. But, I learn more than I would if I were never on Twitter. Also, you can always look back at past users and hashtags and get “news updates” as you please. The search feature is pretty good!
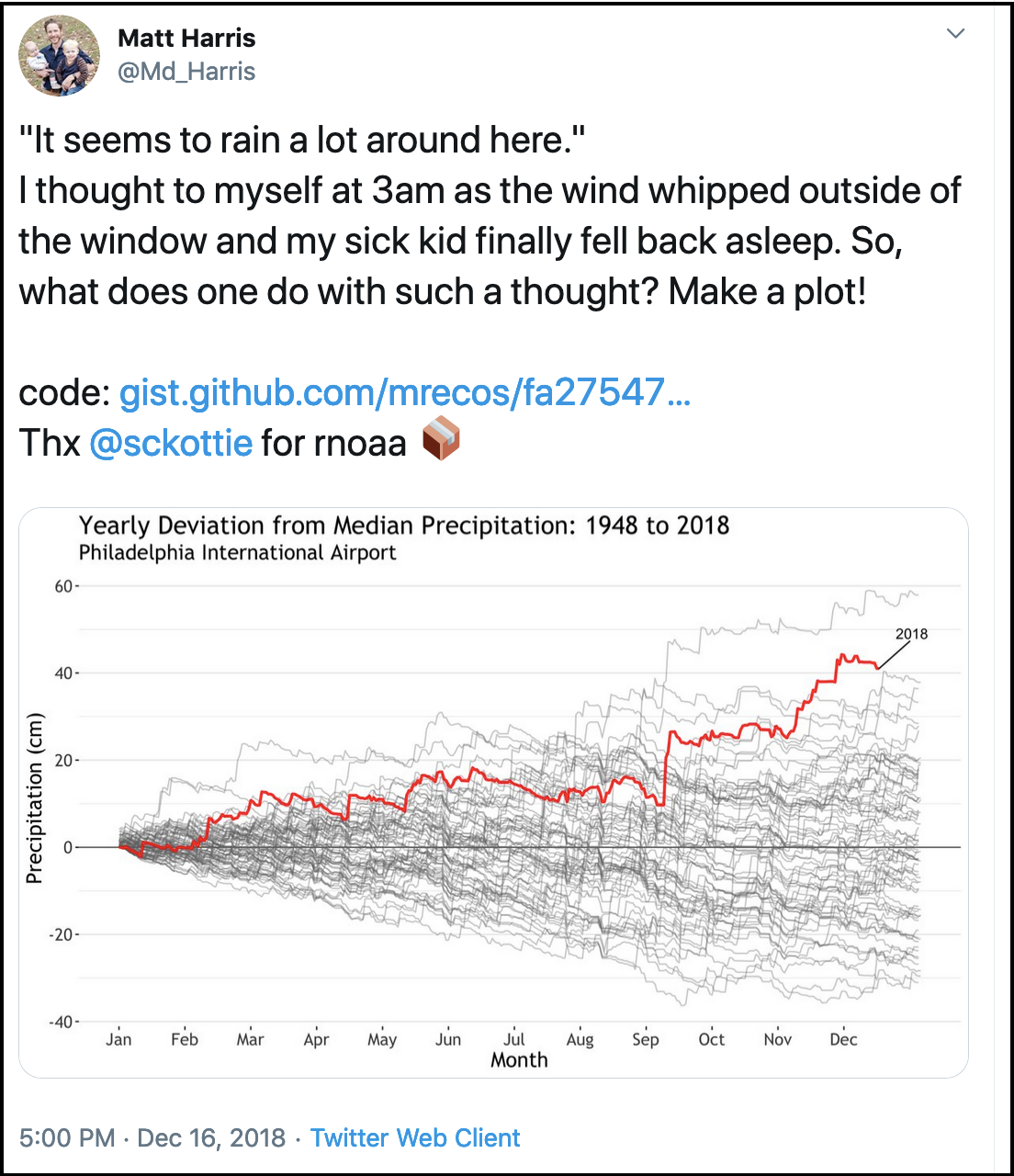
When I saw this tweet by @Md_Harris, this was my internal monologue:
- Cool visualization!
- I want to represent my data this way
- He includes his code that I can look at to understand what he did, and I can run and remix
- The package is from @sckottie — I know he is at rOpenSci, which is a really amazing software developer community for science
rnoaais a package making NOAA [US environmental] data more accessible! I didn’t know about this, it will be so useful for my colleagues- I will retweet so my network can benefit as well
Another example, this tweet where @JennyBryan is asking for feedback on a super useful package for interfacing between R and excel: readxl.
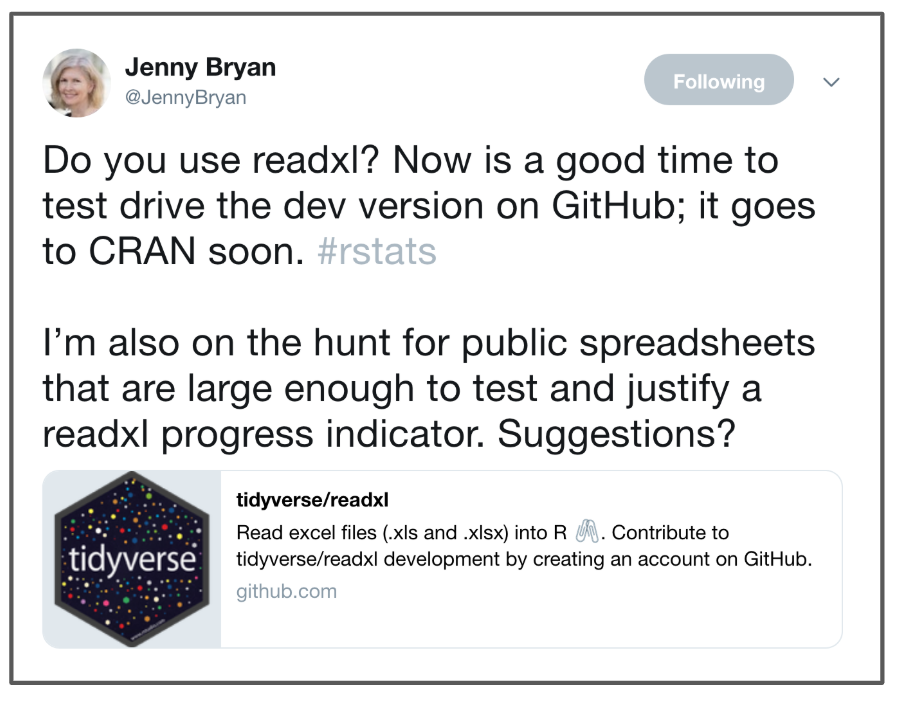
My internal monologue:
- Yay, readxl is awesome, and also getting better
- Do I have any spreadsheets to contribute?
- In any case, I will retweet so others can contribute. And I’ll like it too because I appreciate this work
These are just a few ways to learn and build community on Twitter. And as you feel comfortable, you can start sharing your ideas or your links too. Live-tweeting is a really great way to engage as well, and bridge in-person conferences with online communities. And of course, in addition to engaging on Twitter, check whether there are local RLadies chapters or other R meetups, and join! Or perhaps start one?
As a marine scientist how do we get involved in Openscapes?
Great question :) :). And a great one to end on.
The most immediate thing to join the Openscapes effort and community is to visit the get involved page — there is a signup sheet and you can also follow us on Twitter. I also want to get in front of more marine science & environmental science audiences, to give department seminars and conference talks. It is kind of crazy to me that I’ve given a big talk like this one at useR! but not at any big marine/environmental conferences. Or maybe that’s not surprising since I’m focused on increasing the visibility and value of open data science within environmental science, since it’s not really a “mainstream” conversation yet, like it is in #rstats. In any case, if that is something you can help arrange, please get in touch!
I am currently strategizing and fundraising to build out Openscapes into a full-time, long-term program operated at the US National Center for Ecological Analysis & Synthesis at the University of California Santa Barbara, where I am based. I will be focused on this in the next nine months due to a generous gift from the Moore Foundation following my fellowship support from Mozilla. My goal is to increase the number of research groups Openscapes mentors each year with a small core team and vibrant community. I also want to see about extending/replicating/spinning off Openscapes to other communities (i.e. beyond environmental science). I plan to continue the online cohorts, scaling up as Mozilla Open Leaders has. Additionally, this winter I will lead my first in-person workshop for research groups, adapting the Champions lesson series (and hoping to find time to build that out more too!).
But I’m excited to hear your ideas! Please reach out; I’d love to hear from you.
–
Thanks for reading, and thanks again to everyone at #useR2019!
